Containerizing Data Workflows (And How to Have the Best of Both Worlds)
As a data technology company, Enigma moves around a lot of data, and one of our main differentiators is linking nodes of seemingly unrelated public data together into a cohesive graph. For example, we might link a corporate registration to a government contract, an OSHA violation, a building violation, etc. This means we not only work with lots of data, but lots of different data, where each dataset is a unique snowflake slightly different from the next.
Wrangling high quantities and varieties of data requires the right tools, and we’ve found the best results with Airflow and Docker. In this post, I’ll explain how we’re using these, a few of the problems we’ve run into, and how we came up with Yoshi, our handy workaround tool.
If you work in data technologies, you’ve probably heard of Airflow and Docker, but for those of you who need a quick introduction…
Introducing Airflow
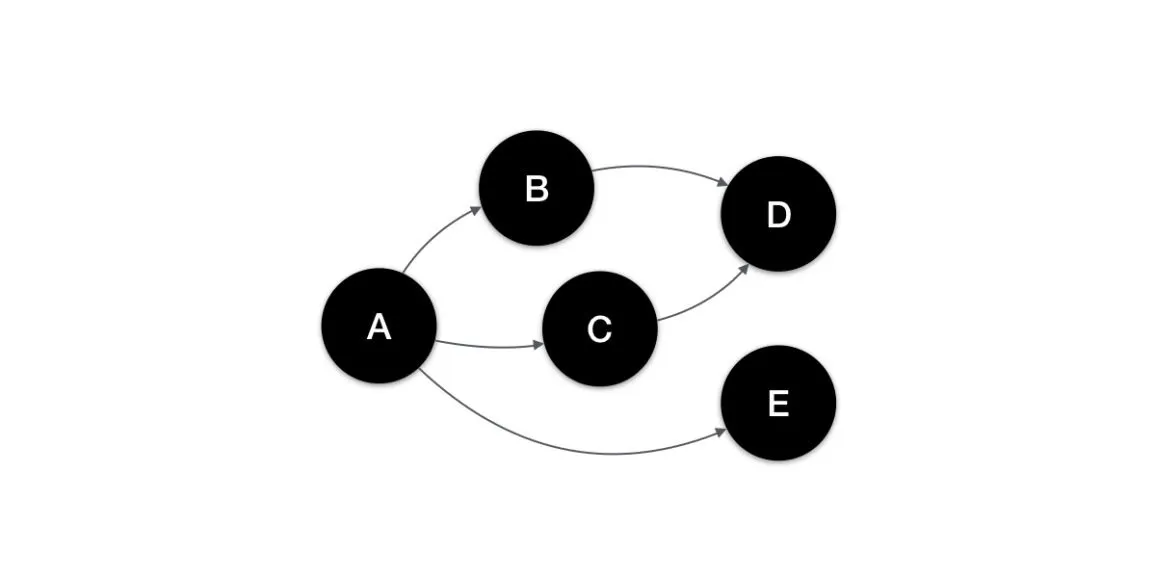
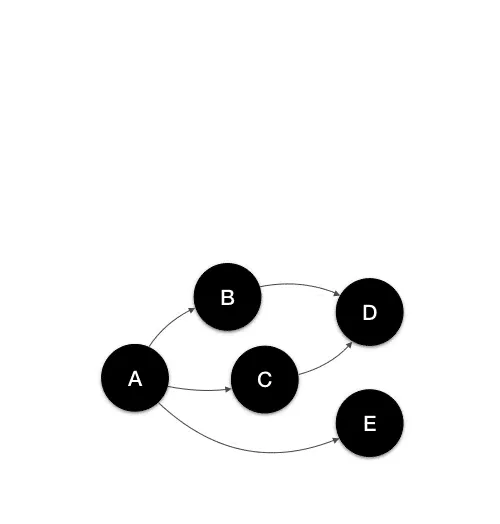
Airflow is designed to simplify running a graph of dependent tasks. Suppose we have a process where:
- There exist five tasks: A, B, C, D, and E, and all need to complete successfully.
- B, C and E depend on the successful completion of A.
- D depends on the successful completion of B and C.
Considering each task as a node and each dependency as an edge forms a directed acyclic graph—or DAG for short.
If you are familiar with DAGs (or looked them up just now on “Cracking the Coding Interview”), you might think that if a DAG can be reasoned within the time of a job interview, then it can’t be that complex, right? In production, these systems are much more complex than a single topological sort. Questions such as “how are DAGs started?” or “how is the state of each DAG saved?” and “how is the next node started?” are answered by Airflow, which has led to its wide-spread adoption.
Scaling Airflow
In order to understand how Docker is used, it’s important to first understand how Airflow scales. The simplest implementation of Airflow could live on a single machine where:
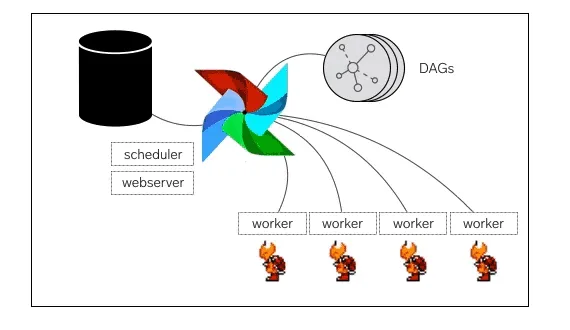
- DAGs are expressed as python files stored on the file system.
- Storage is written to SQLite.
- A webserver process serves a web admin interface.
- A scheduler process forks tasks (the nodes in the DAG) as separate worker processes.
Unfortunately, this system can only scale to the size of the machine. Eventually, as DAGs are added and more throughput is needed, the demands on the system will exceed the size of the machine. In this case, airflow can expand to a distributed system.
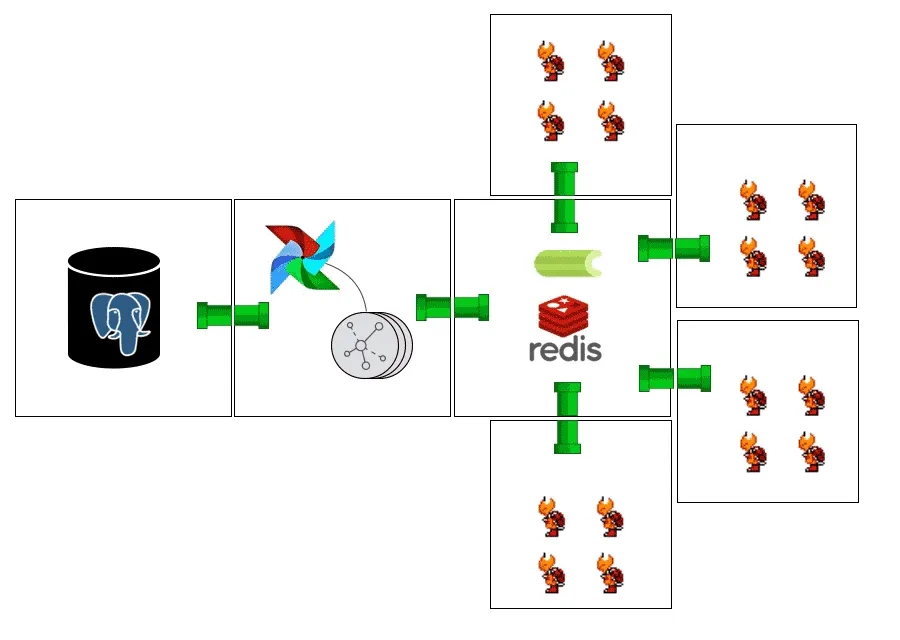
- The airflow webserver and scheduler continue running on the same master instance where DAG files are stored.
- The scheduler connects to a database running on another machine to save state.
- The scheduler connects to redis and uses celery to dispatch work to worker instances running on many worker machines.
- Each worker machine can also run multiple airflow worker processes.
Now this system can scale to as many machines as you can afford,* solving the scaling problem! Unfortunately, switching to a distributed system generally exchanges scalability for infrastructural complexity—and that’s certainly the case here. Whereas it is easy to deploy code to one machine, it becomes exponentially harder to deploy to many machines (exponentially since that is the number of permutations of configuration that can go wrong).
If a distributed system is necessary, then it’s very likely that not only is the number of workers very high, but also the number of DAGs. A large variety of DAGs means a large variety of different sets of dependencies. Over time, updating every DAG to the latest version will become unmanageable and dependencies will diverge. There are systems for managing dependencies in your language of choice (e.g. virtualenv, rubygems, etc) and even systems for managing multiple versions of that language (e.g. pyenv, rbenv), but what if the dependency is at an even lower level? What if it depends on a different operating system?
Containerizing Workflows
Docker to the rescue!
Unless you have been living in a container (ha-ha) for the last five years, you’ve probably heard of containers. Docker is a system for building light-weight virtual machines (“images”) and running processes inside those virtual machines (“containers”). It solves both of these problems by keeping dependencies in distinct containers and moving dependency installation from a deploy process into the build process for each image.

- When the code for a DAG (henceforth, this set of code will be referred to as a “workflow”) is pushed our remote git host and CI/CD system, it triggers a process to build an image.
- An image is built with all of the dependencies for the workflow and pushed to a remote docker repository, making it accessible via URL.
- At the same time, the airflow python DAG file is written. Rather than executing from the DAG directly, it specifies a command to execute in the docker image.
- At run-time, airflow executes the DAG, thereby running a container for that image. This pulls the image from the docker repository, thereby pulling its dependencies.
Docker is not a perfect technology. It easily leads to docker-in-docker inception-holes and much has been written about its flaws, but nodes in a DAG are an ideal use-case. They are effectively enormous idempotent functions—code with input, output and no side-effects. They do not save state nor maintain long-lived connections to other services—two of the more frequently cited problems with Docker.
A Double-Edged Sword?
Docker exchanges loading dependencies at run-time for loading dependencies at build time. Once an image has been built, the dependencies are frozen. This is necessary to separate dependencies, but becomes an obstacle when multiple DAGs share the same dependency. When the same library upgrade needs to get delivered to multiple images, the only solution is to rebuild each image. Though it may sound far-fetched, this situation comes up all the time:
- A change to an external API requires an update in all client applications.
- A security flaw in a deeply nested dependency needs a patch.
- DRY = “Don’t Repeat Yourself” is one of the central tenets of good software development, which should lead to shared libraries.
Code Injection
The double-edged sword endemic to Docker containers should sound familiar to anyone working with static builds. One common approach to solving this problem is to use plug-ins loaded at run-time. At Enigma, we developed a similar approach for Docker containers that we named Yoshi (hence, the Nintendo theme for this entire blog post).

- As previously noted, when a workflow is pushed to our remote git repository and CI/CD system, it triggers an automated process to build an image for that workflow including installing all of its dependencies. Yoshi is a python package that is included as one of these dependencies and gets frozen on the image.
- Since different workflows change at different rates, they go through the build process at different times and wind up with different versions. This is the nature of working with docker images.
- Yoshi is also directly installed onto the machine where the airflow worker runs. The latest version is always installed on these machines.
- At runtime, when the airflow worker executes the docker command, it mounts its local install of Yoshi onto the docker container. This injects the latest Yoshi code into that container, thereby updating Yoshi in the container to the latest version.
By keeping code we suspected might need to be updated frequently in Yoshi, keeping the interface to Yoshi stable and injecting the latest code at run-time, we are able to update code instantly across all workflows.
The Best of Both Worlds?
Injecting code at run-time allowed us to use all of the benefits of Docker containers, but also create exceptions when we needed. At first, this seemed like the best of both worlds, but over time we ran into flaws:
- A stable interface and backwards compatibility are absolutely essential for allowing newer versions of a library to overwrite an older version, but that’s easier said than done. Maintaining compatibility across hundreds of workflows with different edge cases is even more challenging. Coming from working with containerized processes also required forming some new habits. No code is one-hundred-percent bug-free, but this led to many more bugs than we anticipated.
- The most frequent use-case for Yoshi was for clients to access external resources. When external resources changed, Yoshi changed with them, which meant that older versions no longer worked. An image is expected to work forever, but the absence of the latest version of Yoshi broke that expectation.
- Did I say that the most frequent use-case for Yoshi was for clients to access external resources? Turns out that was the only use-case. Initially, we expected to use Yoshi in many different ways, but wound up using it in the same place every time. This meant Yoshi was much larger and more complex than necessary and we only needed it in one node of the DAG.
Yoshi caused more bugs and complexity than we wanted, but by revealing where our code changed most frequently, it also revealed a simpler way to deploy updates across many DAGs.
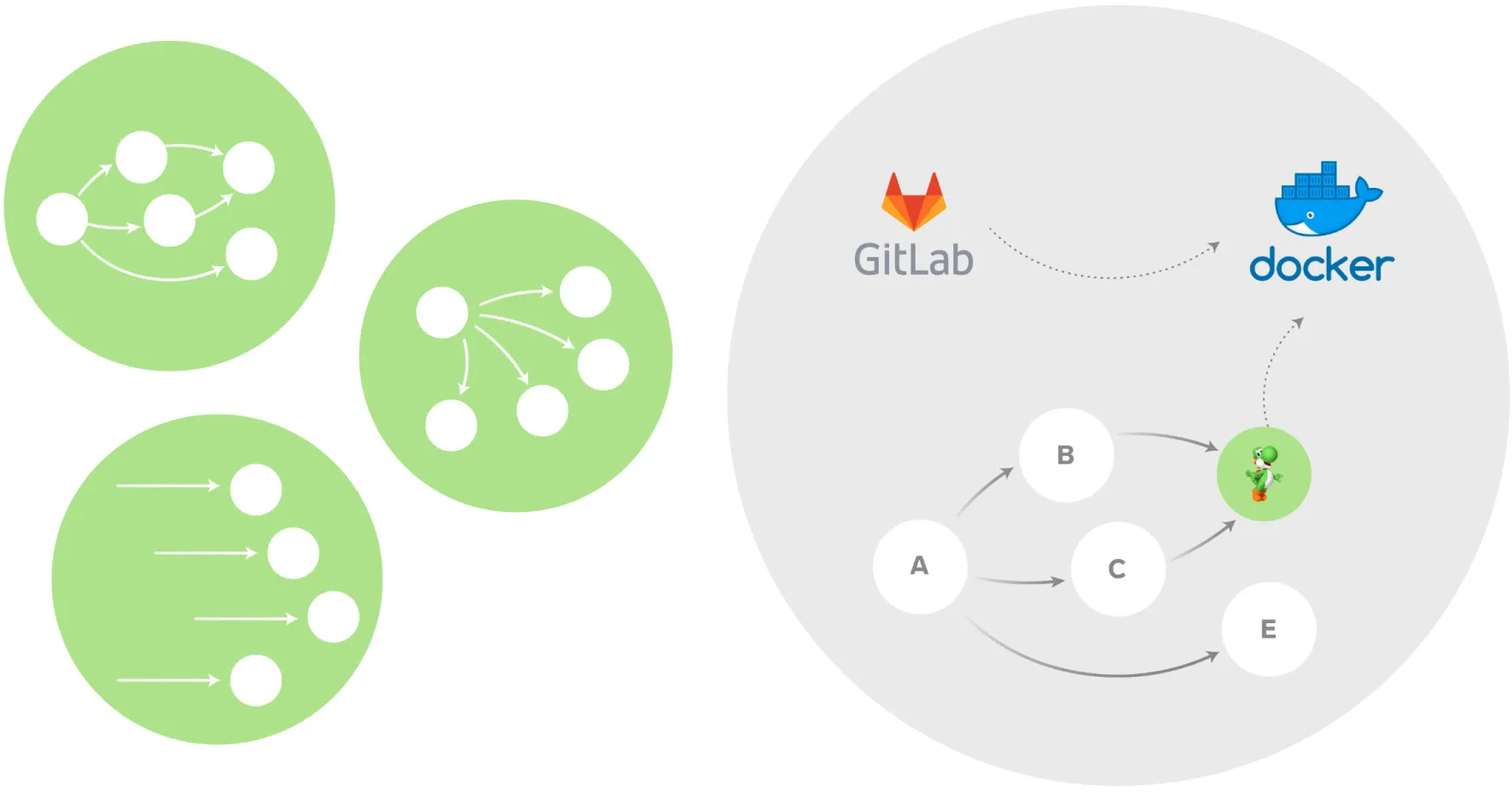
Image Injection
Heretofore, images were built one-to-one for each DAG, but it does not have to be that way. Each workflow has its own set of dependencies, so an image is built for those dependencies, but each node in the DAG could use a different image. Additionally, Docker images are referenced by URL. The image stored for that URL can change without changing the URL. This means that a DAG node executing the same image URL, could execute different images.
Eventually, this led us to inject code by inserting updated images in the middle of a DAG.
- The Yoshi library remained the same, with all of the same functionality, except now it was also packaged and executable from its own docker image.
- Workflows were changed so that individual DAG nodes could use different image URLs. Nodes where our code interacted with external resources now used the Yoshi image instead of the workflow image.
- The URL for the Yoshi image were resolved at run-time with environment variables from the machine so that different environments could use different URLs - e.g. staging could use an image tagged as staging and same for production.
- When changes to the Yoshi library were pushed to our remote git repository, our CI/CD system built a new image and pushed it to the Docker repository at those URLs.
- At run-time, the workflow pulls the latest Yoshi image.
Image injection not only allowed us to build workarounds to the double-edged sword of static Docker images—without the compatibility challenges of code injection—but building a Yoshi image also opened new doors to run Yoshi utilities from a command-line anywhere and run a Yoshi service.
It took us a long time to get there, but our final solution allowed us to have the best of both worlds, and then some.
Game Over.

*There is a limit to the number of machines that can connect to the same redis host, but that is most likely a lower limiting factor - especially for a start-up.