Dev/Stage/Prod is the Wrong Pattern for Data Pipelines
Sometime in the mythical past, we software developers learned that testing in production was a bad idea. We developed a pattern of testing and deployment based on dev/stage/prod environments (or some variant of these concepts):
- dev to integrate our changes
- stage to sanity check that it all worked together
- prod to make it available to customers
The primary benefit of maintaining distinct dev/stage/prod environments is isolation. We can test the impact of our changes in one environment without affecting the one our customers use.
However, for data pipelines of more than moderate complexity, achieving isolation via dev/stage/prod environments leads to predictable problems that we’ll explore below. Fortunately, there is a different pattern that we call a pipeline sandbox that solves these problems.
First, let’s see where the dev/stage/prod pattern breaks down for data pipelines. The key characteristic that makes a data pipeline different from other applications is the time and expense it takes to test. If the pipeline takes multiple hours and thousands of dollars to run, it may take multiple hours to uncover an issue with a change. The place where that change manifests itself may be very far upstream from where we made the change. Other problems include:
- When multiple changes are tested at the same time, it is often difficult to attribute effects we see in the data to a particular change. Diagnosing the specific cause of data issues becomes so difficult that it can paralyze teams.
- While the data pipeline is running, it effectively freezes out other developers from applying their changes. Changing logic while the pipeline is running also risks contaminating a measurement your teammate is planning.
- Data state is difficult to manage in dev/stage/prod environments. The data sets in a pipeline may run into the hundreds of terabytes. Synchronizing data across environments is often necessary for accurate tests on a non-prod environment. Establishing the correct data state at scale is both time-consuming and logically complex.

An alternative to dev/stage/prod is a pipeline sandbox. A pipeline sandbox is a fully functional and fully isolated version of the data pipeline whose logical state corresponds to a git branch.
For a developer working in a pipeline sandbox, the system behaves exactly as if they were developing on the production pipeline except:
- Changes applied on their git branch are only applied to their sandbox
- The data state is writable snapshot of a specific version of the prod pipeline
This gives the developer confidence that:
- The results they observe on their sandbox are consistent with prod
- Any unexpected results are caused by a change they introduced
Assuming we’ve built an efficient data infrastructure, each developer can create a pipeline sandbox in minutes. This relieves developers of the concern that they are interfering with each other’s work during development. After a developer validates their change on their pipeline sandbox they can merge their branch into main and apply to the production pipeline.
Pipeline sandboxes also reduce costs. Developers no longer copy the upstream data for every data state that they create; instead they simply generate a parallel version of the data state from a certain point in time that they can overwrite with their changes.
When changes tested in different sandboxes run together, we may still discover issues because of unexpected interactions among the changes. But this is both a more tractable problem and less likely to occur because we’ve already tested the individual changes in isolation. We also still have the sandbox available to help with our investigation.
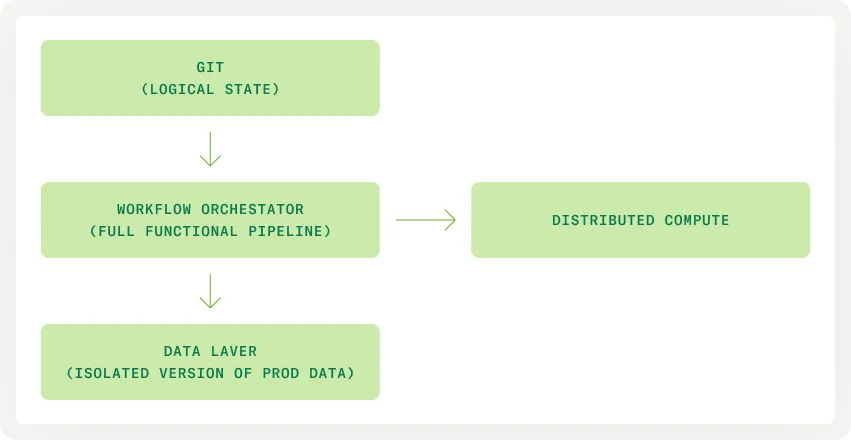
A pipeline sandbox generally consists of the following system components:
- A git branch that contains the complete logical state of the pipeline
- A DAG in the workflow orchestrator that translates this logical state into executable instructions (often these are run in a separate distributed compute environment)
- A writable snapshot of the production data
While creating pipeline sandboxes may sound daunting, great tools have become available in recent years to make this easier. Two of our favorites are:
- LakeFS provides a git-like abstraction over a data lake and makes it easy to efficiently create data branches, which are copy-on-write versions of a pipeline’s data state.
- Dagster is a next-generation workflow orchestration tool that offers both isolated DAGs and data-centric orchestration semantics.
The biggest challenge in creating pipeline sandboxes is consolidating the logic state of the pipeline in a single git repo. Frameworks like dbt that provide consolidated logical state are loved by their users. If you’re not using a framework that consolidates logical state (like us), it’s more challenging to consolidate pipeline state, but still entirely feasible (we’ll cover this in the next blog post).
Although they’re not the right pattern for data pipelines, dev/stage/prod environments still have their place in our data architecture toolkit. Components of the data infrastructure that we manage – such as workflow orchestration environments, metastores, etc. – benefit from dev/stage/prod environments to safely manage upgrades. The distinction is that these are infrastructure components rather than components that define the semantics of our data pipeline.
Empowering developers with data pipelines required significant investment – particularly the task of consolidating our logical state into a single git repo. That investment has paid off in terms of higher team velocity and developer satisfaction. Prior to adopting pipeline sandboxes roughly half our team’s bandwidth was expended dealing with environment issues. We’re now fully focused on improving our business logic, ML models, and performance optimization.