Improving Entity Resolution with the Soft TF-IDF Algorithm

Here at Enigma, we extract signal from public data by linking together many datasets. Often, the datasets are published by different groups, so linking records across them is more difficult than a simple join or merge. This means that our engineering and data science team thinks a lot about how to improve our methods for data linkage.
Recently, we wanted to link the Open Payments dataset, which lists payments that drug and device companies made to doctors, with other healthcare datasets to explore how receiving these payments affect doctor’s behavior (e.g., prescribing, services, and referrals). The datasets describing doctor’s behavior are easy to link with one another because they include the unique National Provider Identifier (NPI) for each doctor. Unfortunately, the Open Payments dataset does not contain the NPI, so we need to link the Open Payments dataset with the Healthcare Licenses dataset to append each doctor’s NPI to the payments information. Once we add the NPI to the Open Payments dataset, we can easily find links between payments and behaviors.
To connect the Open Payments data with the NPI information, we need to match records using the names and addresses of doctors. If the names and addresses are identical across datasets, matching is straightforward – just apply some simple data cleaning and search for exact matches. In our dataset, this naive method matches just over 50% of payments with physicians. Not bad, but looking at some of the non-matched pairs makes it clear that this inflexible matching method overlooks a lot of matches. For instance, do these records describe the same doctor?
SENTHIL K NATARAJAN 1870 WINTON RD S, SUITE 1, ROCHESTER, NY
SENTHILRAJAN KASIRAJAN NATARAJAN 1870 WINTON RD S, STE 1, ROCHESTER, NY
These probably refer to the same person, but in order to link non-exact matches we need to use fuzzy matching to compare text across datasets. A standard fuzzy-matching technique called “Jaro Similarity” measures how close two strings match on a scale of 0 (nothing in common) to 1 (they are exactly the same) by measuring how many edits you’d need to make to convert one string into the other. The Jaro similarity for these two names is 0.78, which sounds pretty good. But if we decided that everything at 0.78 or higher was a match, we’d also end up matching names like MICHELLE RIMPENS with MICHAEL ROBINSON.
Recently, we tested a method that can improve the results of fuzzy-matching. This method, called Soft TF-IDF1, builds on existing fuzzy-matching methods by considering how frequently various letter combinations appear in the data. There are many common suffixes for surnames (e.g., -son, -poulos, -ski) or terms in addresses (e.g., ave, st, suite) that we should downplay—we wouldn’t want to say that two addresses are similar just because they both mention being on an avenue—so we should focus on the things that make names and addresses unique when measuring their similarity. Researchers have found this effective for linking records across datasets, so we were optimistic that the Soft TF-IDF method would improve our ability to connect more doctors with their NPIs.
In the next few sections, we detail how we built a scalable pipeline for linking datasets using the Soft TF-IDF algorithm.
Designing a Scalable, Nuanced Approach
Deciding which observations from each dataset refer to the same doctor is more generally known as entity resolution (ER). Procedures for entity resolution are usually based on advanced string comparisons, such as the Soft TF-IDF, to compensate for noise and imprecision in records across datasets. However, these methods are computationally expensive and would prevent us from scaling up to large datasets if we needed to compare every pair of records across datasets. To help ER scale, we use blocking to more efficiently decide which pairs of records need the more demanding string comparisons and which pairs can be safely ignored.
In the blocking stage, we group similar records together into a “block.“ In the disambiguation stage, we perform the computationally expensive operations within each block to determine which records match. For example, you could parse an address and only perform entity resolution on records that come from the same city because we would be confident that records describing entities in different cities are not the same. This allows you to use powerful (but demanding) matching techniques, like Jaro Similarity or Soft TF-IDF, on large datasets without wasting time comparing records that are clearly non-matches.
Blocking
For our current use case, we perform blocking based on the geographic location of each doctor. We geocoded each address from the Open Payments and NPI datasets to get the latitude and longitude of each location. Using geocoded addresses lets us capture the fact that, 4802 10TH AVE, BROOKLYN, NY is actually the same building as 948 48TH ST, BROOKLYN, NY, despite the addresses looking quite different.
We store the latitudes and longitudes in a tree-based data structure to make it easy to find which addresses are near one another. For two-dimensional data, like latitudes and longitudes, a standard KD-tree organizes the data so it’s easy to find other nearby points. It does this by repeatedly splitting and regrouping data into sets with similar values – it first finds the median latitude and divides the data into two groups, then it finds the median longitude and splits in half again to create four groups. We apply this split-and-regroup process over and over until each group has no fewer than 16 points. By constructing the tree in such a way, we can find nearby points far more efficiently than if we had to look through the entire dataset.
The process for finding points a set distance around a query point is called using the “range query,“ and looks like this:
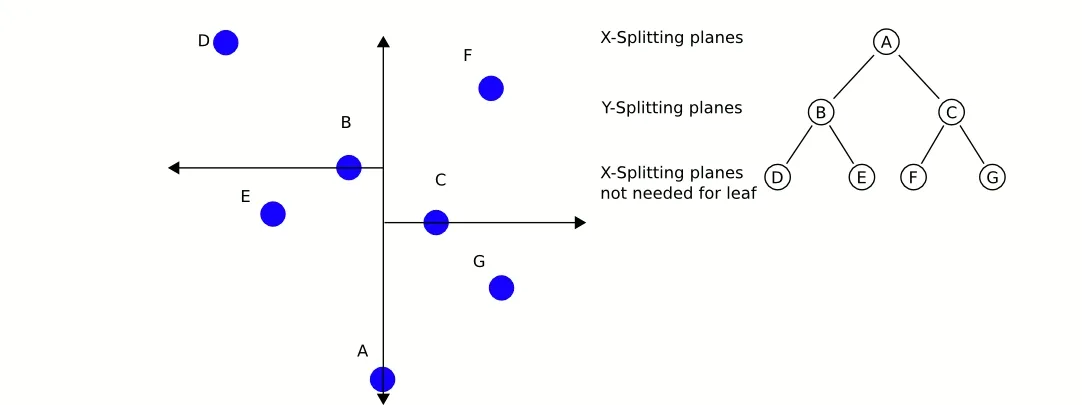
Any point within the circle can be considered part of the entity resolution block for that central point. Tree indexing lets us quickly find these points. Once we find that a node doesn’t contain overlap with the specified range, we know that none of the child nodes can either. By starting at the highest regions, we can quickly eliminate most of the data for being too far away.
For the blocking phase in our ER pipeline, we use the range query to find all the potential matches for a doctor’s address in the Open Payments dataset by looking at the addresses for with NPIs that are within 100 meters (approximately the size of a city block). Then, disambiguation proceeds on this small group of potential matches.
This hyperlocal blocking is fast to implement, given the tree structures and geocode-able data, and greatly reduces the number of string comparisons needed during disambiguation. If we didn’t use any blocking, we would need to perform billions of computationally expensive string comparisons on doctors. But, using this blocking strategy filters out most of those comparisons. Billions of potential string comparisons are reduced to only about 260,000 comparisons, a reduction of over 99.999%.
Disambiguation
After the blocking method identifies potential matches based on doctor’s address, we do pairwise comparisons of doctors names to determine which potential matches are actual matches. We compared two similarity measures in the disambiguation phase: the standard Jaro Similarity, and the Jaro Similarity plus the Soft TF-IDF algorithm mentioned above.
Regardless of which similarity metric you use, you will need to decide on a threshold for determining how similar entries need to be in order to be designated as a match. This decision always comes with a tradeoff. A low threshold will find more matches, but also more false positives, while a high threshold will result in the opposite. For our case, we want to minimize the number of false-positives to be certain we are accurately connecting doctors and payments, so set relatively high thresholds.
Results
We decided to focus on doctors in New York, Enigma’s home state, to compare ER pipelines using Jaro Similarity alone and including both Jaro Similarity and Soft TF-IDF for disambiguation. The Healthcare Licenses dataset has 385,573 New York healthcare professionals and Open Payments lists 49,033 unique New York doctors.
Using standard Jaro similarity as a baseline, we matched 37,406 doctors with an NPI. Using both Jaro similarity and the Soft TF-IDF algorithm increases this number to 38,640—that means we found matches for ~1,200 more doctors before! We manually reviewed a sample of the matches for each method and found very few false-positives in either (fewer than 1% of matches). So, incorporating the Soft TF-IDF method was the clear winner because it was able to find more matches without increasing our false positive rate. We were able to match about 80% of payments to physician NPIs, a huge step up from the 50% we were able to match with with naive exact matching.
How Soft TF-IDF Similarity Works
Now that we’ve demonstrated the benefits of using the Soft TF-IDF method in comparison to standard string similarity metrics, let’s explore what’s happening under the hood. Below, we’ll walk through the mathematical explanation of the Soft TF-IDF algorithm. If you’re less interested in the mechanics, feel free to skip this section.
Soft TF-IDF is very similar to the standard TF-IDF algorithm, which can be used to evaluate the similarity of two records by considering how frequently they occur in the data. Except, now we’re also letting tokens that almost match count, too. It was introduced in Cohen et al (2003), and there are a few ways to implement it. We’ll walk through one version, shown below.
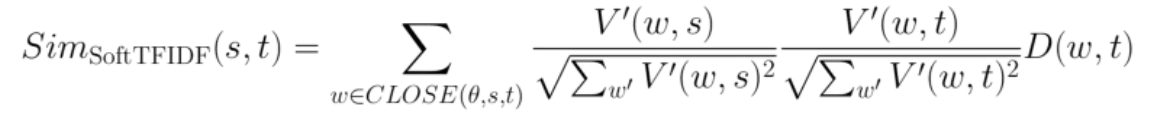
The formula looks intimidating, but looking at each component independently makes it significantly more clear. Let’s dive in.
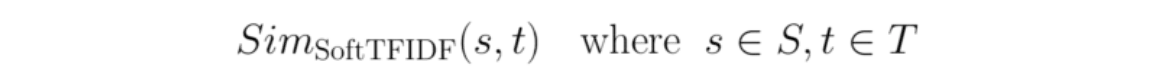
We want to compare two strings, s and t, that come from corpuses S and T, respectively.
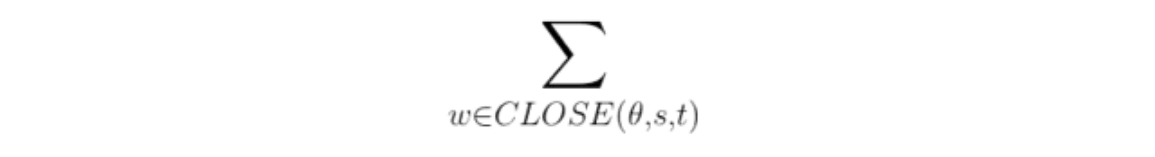
If we’re comparing two strings, and we see a token is in s but not t, we probably don’t want that token to increase our similarity score. But, we mightwant to use it if it almost matches another word, depending on how close the match is. So, we can build our similarity measure by only considering the subset of tokens that match something in the other set above a threshold θ. Typically, we would use a standard similarity measure (such as the Jaro Similarity) to make these “first level” string comparisons.
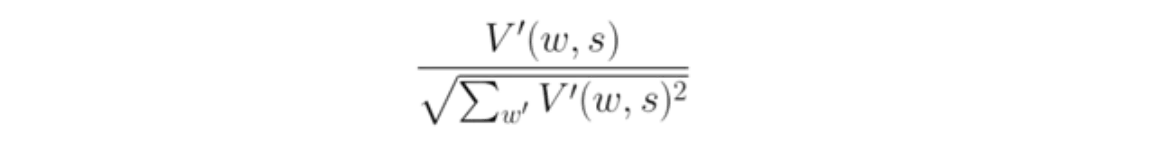
V’(w,s) is defined as the TF-IDF weight of token w in string s, computed based on the entire corpus S. We then normalize by the square root of the sum of all the squared V’s (one for each token) in the set.
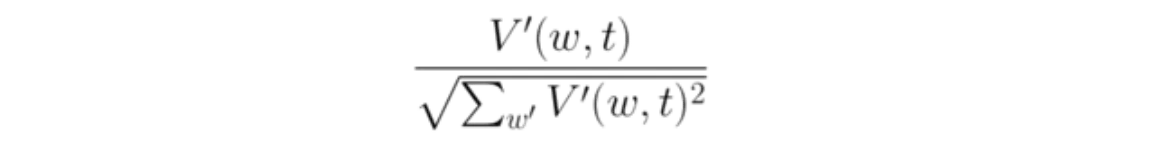
This is the same as above, but for the token from set T.
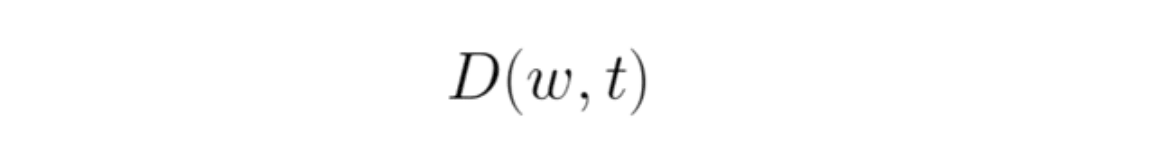
This term is the measure of similarity (using the “first level” similarity measure) between the token and the token it matched to in the other set. As a result, D(w,t) is essentially a normalizing coefficient, which dampens the impact on the Soft TF-IDF (“second level”) similarity from words that matched with low “first level” similarities. For example, if two tokens matched with a score of 0.9, D would be set to 0.9.
By putting this all together again, it’s clear that the total similarity is just the combined similarity scores of the all matching tokens. And that’s all there is to it. This is Soft TF-IDF, the nuanced method we need to better compare two strings from different corpuses. With standard approaches and Soft TF-IDF, we’ve got exactly what we need for enhanced linking.
Because this approach uses the TF-IDF weighting of tokens in the strings, it can match records that standard Jaro-Similarity matching would miss without introducing false positives, such as our original example:
SENTHIL K NATARAJAN 1870 WINTON RD S, SUITE 1, ROCHESTER, NY
SENTHILRAJAN KASIRAJAN NATARAJAN 1870 WINTON RD S, STE 1, ROCHESTER, NY
Dr. Natarajan is just one of the many additional matches we can now make.
Final Thoughts
Implementing Soft TF-IDF to augment standard metrics like Jaro Similarity helped us uncover ~1,200 new matches in public data without overwhelming us with false matches. By effectively linking data, it’s possible to better investigate important questions such as whether payments affect doctor behavior or whether a business is riskier than it seems on first glance.
We’re constantly improve our linking capabilities and empowering our clients to make more intelligent decisions by seeing the whole picture. If you think working on that sounds cool, we’re always searching for talented Data Scientists and Software Engineers.