Mapping the World of Package Management

In late 2020, we started having difficulties with the installation of Python packages.
At times, the default package manager for Python, pip, would take hours for what used to take seconds. Worse, it might just refuse to install the packages altogether, with an error message indicating a version conflict.
With 15 applications and 19 internal libraries in our small business data processing pipeline, all of them written in Python and spread out over as many git repositories, humans and machines alike need to install packages with reasonable regularity — the humans to develop new versions of the code, and the machines to create container images for deployment to production, typically as part of continuous integration.
It wasn’t too difficult to identify the proximate cause for this highly unusual slowdown. Version 20.3 of pip had been released on November 30, 2020 and included a change of package resolution algorithm. The previous and fundamentally unsound “pick pretty much any version” algorithm was now disabled by default and marked for removal in a future version. Its replacement treated version constraints as gospel truth and refused to install dependencies when those version constraints were in conflict. That there were version conflicts in our codebase wasn’t surprising. After all, the version constraints appearing in manifests had never been validated for global consistency. Hence it was unavoidable that this transition would be somewhat rough.
It didn’t help that the pip team buried the news about switching to the new package resolver as default: it is the second-to-last item in the list of features updated for the preceding beta release 20.3b1. Furthermore, with a public preview period of only four months, the pip team made the switch too early. The resolver was still prone to exhaustively exploring versions that would never satisfy the constraints. It also contained at least 19 bugs and shortcomings that were then fixed over the following twelve months — compared to 14 that were fixed during the preview period.
A further source of confusion was that most engineers use the version of pip bundled with Python’s standard library. That makes the version of pip used to install packages dependent on the version of Python used to run code, while also introducing a significant delay until any given version of pip becomes widely used. Notably, if you are using Python 3.7 (as some of us still do) and ignore the pip warning exhorting you to upgrade, you are still using the old resolver to this day. If you are using Python 3.8 (as some of us also do), then the release of Python 3.8.10 on May 3, 2021 fundamentally changed how you install Python packages. The apparent disregard in all this for established versioning conventions is striking. Making backwards incompatible changes in a new minor version (pip 20.3) or in a new patch version (Python 3.8.10) is a big no-no under semantic versioning and not helpful.
As exasperated tales about pip’s misbehavior multiplied in our daily standup meetings, it became clear that we needed to start a concerted effort towards cleaning up our package requirements. At the same time, we had little insight into the scope of the clean up, i.e., the number of packages with conflicting versions as well as the number of conflicting constraints for each conflicted package. So I found myself tasked with producing just that survey in October 2021.
Alas, I couldn’t be bothered with the tedium of manually surveying 34 repositories for their requirements. So I decided to write a Python script for doing the survey and thereby set off on a journey into the wondrous world of package management.
The exploration revealed that the world of package management is large, covered in harsh terrain, and crawling with dragons.
At the same time, there are few maps of this world and they all suffer from significant inaccuracies and omissions. So we decided to follow in the footsteps of early map makers for Earth — Anaximander! Hecataeus of Miletus! Isidore of Seville! — and map the world of package management more completely and accurately, across a series of blog posts.
- This first post will give you a coarse overview map of package management, describing common features found across most terrains and locating the largest and most persistent dragon infestation found in this world. It also identifies the other ferocious critters haunting Python’s package ecosystem, which goes some way towards explaining that ecosystem’s dismal reputation.
- The second post will argue for maintaining your own custom maps and leveraging them to prevent dragon infestations. It will chronicle the transformation of a simple script for extracting package requirements from 34 version control repositories into a checking tool that is based on the dragon-repellent design of Go’s package manager and validates every merge request for those 34 repositories.
- In the third post, we’ll discuss two additional map layers that are critical to understanding this world: the social and economic considerations related to package management, which serve as dragonbane and dragonwort, respectively.
I hope that our map-making efforts help you to better navigate the world of package management and avoid being attacked by dragons along the way. If our maps fall short of that lofty goal, then please remember that the likes of Anaximander (living in Miletus ca 600 BCE) and Isidor (living in Seville 1,200 years later) got a lot wrong as well.
Such are the risks when mapping previously uncharted lands.
A Simple Survey
A world map popular during the Middle Ages is the T-O map by Isidor of Seville. It was originally drawn ca. 636 CE but is shown here in its first printed version from 1472 CE. Source: Wikimedia, public domain.
{kind=link}
Whenever we find ourselves on a journey into new and uncharted lands, it helps to draw a map. That way, we won’t get lost later on. For that to be the case, the map must be sufficiently accurate and detailed. Otherwise, we end up with a map like the T-O map by Isidor of Seville from 636 CE shown above. It clearly lacks detail. In fact, there isn’t any. At the same time, it isn’t as outlandishly inaccurate as you might think. If you take an orthographic projection of Earth with Jerusalem at the center, draw in the western half of the equator and the full meridian, rotate the map by 45º counter-clockwise, you end up with the map shown below. Et voilà, the T-O map is not that different from a modern map anymore.
An orthographic projection of Earth with Jerusalem as the center rotated by 45º counter-clockwise. Source: Wikimedia, public domain.
{kind=link}
Let’s return to package management and start by defining our terminology. A package is an archive file that contains software that has been prepared for distribution. That software may be a complete application or command line tool, but quite often it only is a building block or library. Code may be in either source or binary form and targets either a particular programming language or operating system. Each package has a unique name and each release of the package has a hierarchical version number.
As you already saw above on the examples of pip 20.3 and Python 3.8.10, the version number typically uses dots to separate the major, minor, and patch numbers. In the case of Python 3.8.10 the trailing zero is meaningful: this version is the eleventh patch release of Python 3.8. Another software artifact depends on that package when it may possibly execute some of its code. To do so, the artifact requires the package by listing the dependency in its manifest. Each entry in that manifest names the dependent package and optionally also includes constraints on suitable package versions as well as the runtime environment.
The package manager implements the mechanics of a package ecosystem. Its primary two functions are to publish packages to some package registry and to install the dependencies of a software artifact by consulting that registry. Publishing a package requires a deliberate decision by the package’s developers or maintainers that the current state of the package’s code is worthy of consumption by others. The mechanics of publication include creating the required manifest and archives as well as uploading them to the registry.
Installing a package also requires a deliberate decision by the package’s users to build on a package’s contents. However, most package managers support the automatic installation of (some) package updates. The mechanics of installation include picking satisfactory versions for all dependencies, locating and downloading the corresponding archive files, validating their cryptographic hashes to establish integrity, and putting their contents into the right file system directories.
We can see why package managers have become so popular. They remove a lot of friction from the process of publishing and consuming software components, while also offering an embarrassment of riches in software packages for all use cases and purposes. Gone are the days when, at least on Unix-like operating systems, one had to search the internet for suitable code, locate a distribution mirror, download the source archive, expand the contents into a working directory, and execute the GNU Build System incantation:
./configure
make
make install
Hence it should be no surprise that package managers have become integral to contemporary software engineering. However, since most commercial corporations prefer not to share (all) their software with the commons, they typically prevent direct access to the package registry and instead use a local proxy that prevents external publication while also auditing the consumption of external packages.
For example, Enigma maintains its own internal Python package registry that is not accessible from outside the firm. That registry is used to publish internal packages. It also proxies access to the Python Package Index (PyPI) serving as public registry, which enables the 15 tasks and 19 internal libraries making up our small business data pipeline to depend on 220 external packages, comprising 60 direct dependencies and the transitive closure of their dependencies.
Hic Sunt Dragones: Here Be Dragons

Detail from the Hunt-Lenox Globe 1510 CE with the inscription at the center stating H(i)c Sunt Dracones: **Here Be Dragons. Source: New York Public Library / University of Rochester, public domain.
All that removal of friction comes at a price. The Hunt-Lenox Globe shown above is kind enough to point out where the dragons are hiding. Sam Boyer, who implemented most of the (by now deprecated) dep dependency manager for Go, created the equivalent blog post for package management. He doesn’t just point to the dragons. He warns us to stay away right at the start, titling the first section “Package management is awful, you should quit right now.” — Ooh, a challenge? This will be interesting and, yes, also fun! But we should still map out where all the dragons and other nasty critters are hiding.
The Dragon Boss: Installing Packages
We’ll spend the rest of this post wrangling the biggest dragon related to package management: installing packages. Fundamentally, it requires determining the transitive closure of an application’s declared dependencies. That includes the packages required by the application, the packages required by the packages required by the application, and so on until a fixed point is reached. Doing so is necessary just for functional completeness, so that the application has all the code it might execute readily and locally available.
The package manager also needs to figure out the correct versions of all packages to install. That is because any practical package ecosystem doesn’t just distinguish between different packages, which usually have a descriptive name, but also distinguishes between different versions of a package. Accommodating different versions is necessary to accommodate ever-present change. Versions are usually named by a three-part hierarchical number. For example, Amazon recently released version 1.23.50 of its botocore Python library for accessing AWS. Remember that the third, least significant component of that version number is 50, i.e., the zero is meaningful and the preceding version is 1.23.49.
When packages declare a requirement in their manifest, they provide a package name, a comparison operator, and a version number. For instance, the requirement “botocore >= 1.19.21” indicates that the application or library requires version 1.19.21 or later of the botocore package. As I described in a previous blog post, that is the first version to include a fully working implementation of the adaptive retry logic, which greatly simplifies the development of robust client code.
Now another library may also depend on botocore but specify “botocore >= 1.15.0” as a requirement. Now, since both requirements appear in the transitive closure of dependencies, our package manager must pick a version that meets both constraints — such as the larger of the two minima, which is version 1.19.21. Conversely, if the constraints cannot be satisfied by a single version, the package manager should report back with an error message that clearly states the unsatisfiable constraints, so developers can adjust the requirements.
Picking a suitable version is rarely as easy as in the above example. First, determining the transitive closure of packages to install and resolving version constraints interfere with each other: different versions of a package may require different packages. Second, the problem of resolving version constraints is NP-complete. In other words, version satisfiability is one of many problems that are equivalent to each other and have no known efficient solution.
At the same time, that class of problems has another, more helpful characteristic: when given a possible solution, we can efficiently verify whether the candidate is in fact a solution. In a pinch, then, we have a general but exponential time algorithm for computing a solution: enumerate all possible solutions (the expensive part) and verify each one of them (the efficient part). If a candidate holds up to scrutiny, we use that as the solution. If we run out of candidates, there is no solution. At least, that’s the theory.
In practice, the dependency graphs formed by package requirements and their version constraints often aren’t that big, and hence even that exhaustive search remains computationally manageable. Also, there is nothing preventing us from being clever and using heuristics that tend to produce a result sooner than mindless enumeration (but won’t always work). Options include SAT solvers, which solve the equivalent problem of boolean satisfiability and have gotten darn good at doing so, in part thanks to yearly competitions, as well as domain-specific algorithms.
Alas, practice cannot escape theory: the cliff of worst-case exponential performance remains very real — as our hours-long pip runs illustrate. Worse, the NP-completeness of the problem domain becomes a barrier to developing other tools, such as our dependency checker.
During development of some of the gnarlier analysis code in our dependency checker, I was seriously exploring the feasibility of extending a symbolic reasoning engine with a theory of version numbers. When that seemed a tad impractical for a weekend project, I started looking for package management algorithms that trade a reasonable loss in constraint expressivity for a gain in guaranteed performance. Lo and behold, I found Go’s module system, which restricts the expressivity of version constraints to no more than what’s required and gains predictable results computed in time linear to problem size in return.
But before it gets better, it gets a whole lot worse.
Python Packaging: From Dragons to Superfund Site
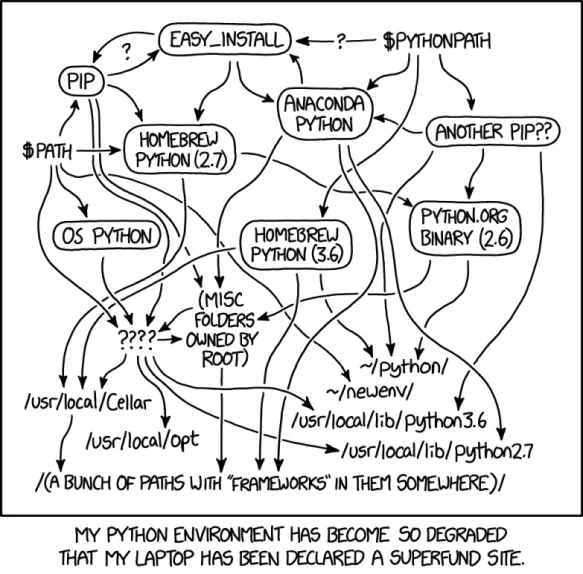
An overview of Python packaging. Names and versions have changed a bit since April 30, 2018 CE when this xkcd comic first appeared. Nonetheless, it remains a mostly accurate description of the state of the art for Python package management. Source: xkcd.com,CC BY-NC 2.5. Our sincere thanks to Randall Munroe for allowing us to reproduce this comic.
The above xkcd comic provides an approximate map of possible Python installations for a computer. In doing so, it also provides a first indication that Python’s package ecosystem is quite a bit more complicated than others. In fact, if anything, the above map is too simplistic. Python has six officially supported installation schemes, each of which comprises eight different paths. So-called virtual environments modify those paths even further and cross-compiling between environments is possible only with officially unsupported hacks. The difficulties don’t stop there. Additional complicating factors, roughly ordered from less to more severe, include:
- Version numbers have several uncommon attributes, notably epochs and post releases, that complicate reasoning about versions without providing any additional expressivity.
- Version constraints support an uncommon operator, the arbitrary equality operator ===, that has Python semantics and thus is hard to model outside a Python interpreter.
- Environment markers further constrain requirements to, say, specific Python versions, Python interpreters, or operating systems. The number of distinct such environments deepens the complexity of dependency analysis.
- Version numbers have no semantics, only an ordering. While that fulfills the minimum requirements for version satisfiability being computable, it also does not help with gauging the impact of any version increase. That, in turn, results in highly confusing scenarios — such as the one described above, where a patch release of Python (3.8.10) contains a minor release of pip (20.3) that includes a groundbreaking, completely backwards-incompatible feature.
- Packages traditionally do not include their dependencies with the metadata. One must first download and build the package. This considerably slows down version selection and wastes tremendous network and package registry resources.
- Packages traditionally specify their metadata in code, not in data. That makes it nearly impossible to extract the metadata without running arbitrary code, including package-specific plugins.
What you get is a package ecosystem with a poor developer experience that makes tool building much harder than necessary. Worse, the ecosystem saw few improvements during Python’s “lost decade” — when most packages supported two incompatible versions of the language and which lasted, roughly, from the first production release of Python 3 in December 2008 to the last production release of Python 2 in April 2020.
Thankfully, things are improving as of late and the rate of improvement is seemingly accelerating. Notably, support for pluggable build backends and the definition of a more realistic common metadata standard are significant steps towards a simpler Python package ecosystem.
Still, Python could do so much better if it rid itself of much of this cruft more aggressively while also rethinking foundational aspects more radically.
The site-specific map-making effort described in part two of this blog series will serve as partial proof of concept that doing so is feasible and has significant upsides.